ALGORITHMES DE TRIS: SUITE¶
Introduction¶
La séquence précédente portait sur l’étude comparative des algorithmes de tri à coût quadratique. Rappelons qu’un coût quadratique est en ${\tt O\big(n^2\big)}$ et signifie qu’un doublement de la dimension de l’objet à traiter multiplie par 4 le nombre d’opérations c’est à dire le temps de traitement (${\tt n}$ est la taille du tableau). Cette nouvelle séquence a pour objectif l’étude de deux algorithmes de tri à coût quasi-linéaire soit en ${\tt O\big(n\ln(n)\big)}$.
Les courbes suivantes permettent de visualiser la différence de comportement entre ${\tt n^2}$ et ${\tt n\ln(n)}$.
from matplotlib.pyplot import plot, clf, show, legend, rcParams, figure
from math import log
from time import time
rcParams['text.usetex'] = True # pour afficher des symboles mathématiques avec Latex (dans la légende)
figure() # on crée une nouvelle figure
X = [] # abscisses
Y = [] # ordonnées
Y2 = [] # ordonnées
for k in range(10,210,10): # k va de 10 à 200 par pas de 10
X.append(k)
Y.append(k**2)
Y2.append(k*log(k))
plot(X, Y, label='courbe de $n\longmapsto n^2$', marker='+', markersize=10, linewidth=2, color ='r')
plot(X, Y2, label='courbe de $n\longmapsto n*\ln(n)$', marker='+', markersize=10, linewidth=2, color ='g')
legend()
show()
1. Rappel - Comment échanger deux valeurs dans un tableau en Python ?¶
Rappelons qu'il existe deux syntaxes possibles pour échanger la valeur de deux variables ${\tt a}$ et ${\tt b}$.
a = 1234
b = 6789
a = b
b = a
print(a, b) # ECHEC de l'échange
a = 1234
b = 6789
x = a # on mémorise la valeur de a dans une variable auxiliaire
a = b # la valeur de a est écrasée par la valeur de b
b = x # on récupère l'ancienne valeur de a grâce à la variable x
print(a, b) # cette méthode est valable avec n'importe quel langage de programmation
a = 1234
b = 6789
a, b = b, a # affectation simultanée: Python évalue le membre de droite et l'affecte au membre de gauche
print(a, b) # cette méthode élégante est valable uniquement avec le langage Python
Pour échanger deux valeurs dans une liste Python la syntaxe est la même. Par exemple pour échanger la première et la cinquième valeur:
L = [ 2*k+1 for k in range(10 )] # liste définie par compréhension
print(L) # liste des 10 premiers entiers impairs
On échange ${\tt L[0]}$ et ${\tt L[4]}$.
x = L[0]
L[0] = L[4]
L[4] = x
print(L)
Ou plus simplement:
L[0], L[4] = L[4], L[0]
print(L) # on fait deux fois le même échange donc les éléments ont repris leur place
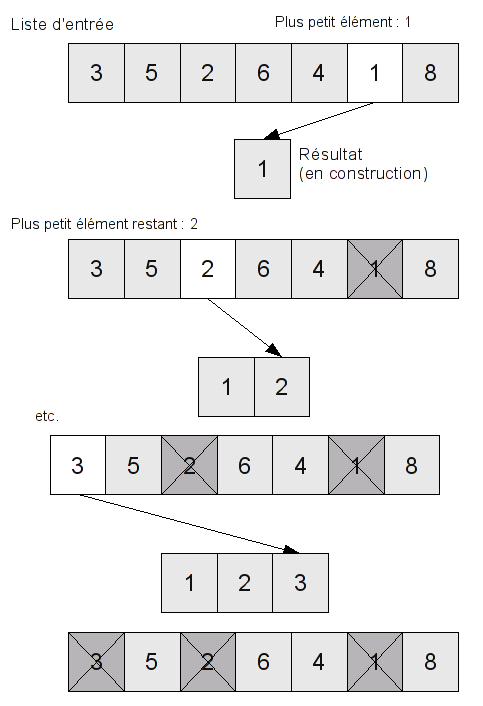
Rappelons le principe du tri par sélection.
- On détermine l'élément minimum du tableau, puis on l'échange avec le premier élément du tableau.
- On recommence l'opération avec les éléments d'indices ${\tt 2}$ à ${\tt n}$ puis avec les éléments d'indice ${\tt 3}$ à ${\tt n}$ $\dots$ jusqu'aux élémente d'indices ${\tt n-1}$ et ${\tt n}$.
def triselection(T):
n = len(T)
for i in range(n-1):
# calcul de l'indice où se trouve le minimum de la liste [ T[i], T[i+1], ... , T[n-1] ]
indMin = i
for j in range(i+1, n):
if T[j] < T[indMin]:
indMin = j
# ici on sait que le minimum est en indice indMin
# on l'échange avec l'élément donc l'indice est i
T[i], T[indMin] = T[indMin], T[i] # affectation simultanée
Cette fonction modifie la liste ${\tt T}$ en place: aucune autre liste n'est utilisée et c'est la liste initiale qui est modifiée (et donc pas besion de renvoyer une nouvelle liste en sortie avec ${\tt return}$).
On peut veut proposer une version récursive de cet algorithme: elle va créer en mémoire de nombreuses listes lors des appels récursifs, mais elle sera beaucoup plus élégante à lire.
Pour cela on rappelle que si ${\tt T}$ est une liste on obtient la même liste privée de ${\tt T[indMin]}$ avec la syntaxe ${\tt T[\;:indMin\,]+T[\,indMin+1:\;]}$
La close d'arrêt est donnée par les listes vides ou de taille $1$. Pour une liste de taille quelconque on met son élément minimum en première position et on la concatène avec la liste restant triée récursivement.
Q1. Compléter le code suivant:
def TriSelectionRecursif(L):
if len(L) <= 1: # close d'arrêt: liste vide ou à un seul élément
return ............
else:
n = len(L)
# on calcule l'indice indMin du minimum de L
indMin = .........
for j in range( ... , ... ):
if ......... :
.........
# on renvoie la liste commençant par L[indMin]
# suivi de la liste L privée de L[indMin] triée récursivement
return .................. # appel récursif
# Cellule pour tester
L = [3, 5, 2, 6, 4, 1, 8]
L2 = TriSelectionRecursif(L)
print(L2)
On note ${\tt c_n}$ le nombre de comparaisons effectués par l'algorithme récursif dans le pire des cas, pour une liste de taille ${\tt n}$.
Q2. Justifier que ${\tt c_{n+1} = n-1+c_{n}}$. En déduire que ${\tt c_n= \dfrac{n(n-1)}{2}+c_0}$ puis que ${\tt c_n=O(n^2)}$.
On retrouve donc la même complexité que pour la version itérative implémentée à la séance précédente.
Les "tableaux" sont manipulés sous forme de listes Python.
On choisit dans la liste ${\tt L}$ un élément particulier (en général le premier), appelé pivot: ${\tt pivot = L[0]}$.
On crée alors deux sous-tableaux : ${\tt Linf}$ contenant les éléments strictement inférieurs à ${\tt pivot}$, et ${\tt Lsup}$ contenant les éléments supérieurs ou égaux à ${\tt x}$.
Par exemple: avec ${\tt L = [8, 1, 5, 14, 4, 15, 12, 6, 2, 11, 10, 7, 9]}$ on choisit comme pivot ${\tt pivot = 8}$ et on construit ${\tt Linf}$ et ${\tt Lsup}$:
On relance le tri de manière récursive sur ces deux listes qui deviennent donc des listes triées:
On n'a pas à s'occuper de comment elles ont été triées: c'est la magie de la récursivité! 🪄 🪄
${\tt LinfTri}$ est constituée des éléments ${\tt < pivot}$ et ${\tt LsupTri}$ est constituée des éléments ${\tt \geq pivot}$, on obtient donc simpement la liste initiale sous forme triée en ajoutant ${\tt pivot}$ à la fin de ${\tt LinfTri}$ puis en concaténant avec ${\tt LsupTri}$:
Cet algorithme est un exemple d’une méthode générale utilisée en récursivité, appelée diviser pour régner: on divise le problème initial en deux sous-problèmes qu’on sait résoudre, et on revient ensuite au problème initial.
Dans le cas du tri rapide, les appels récursifs sont lancés jusqu’à tomber sur des listes de taille 1 ou 0, qui sont déjà triées (ce sont les closes d'arrêt), et il ne reste plus qu’à les concaténer dans le bon ordre.
Voici une réprésentation des appels récursifs:
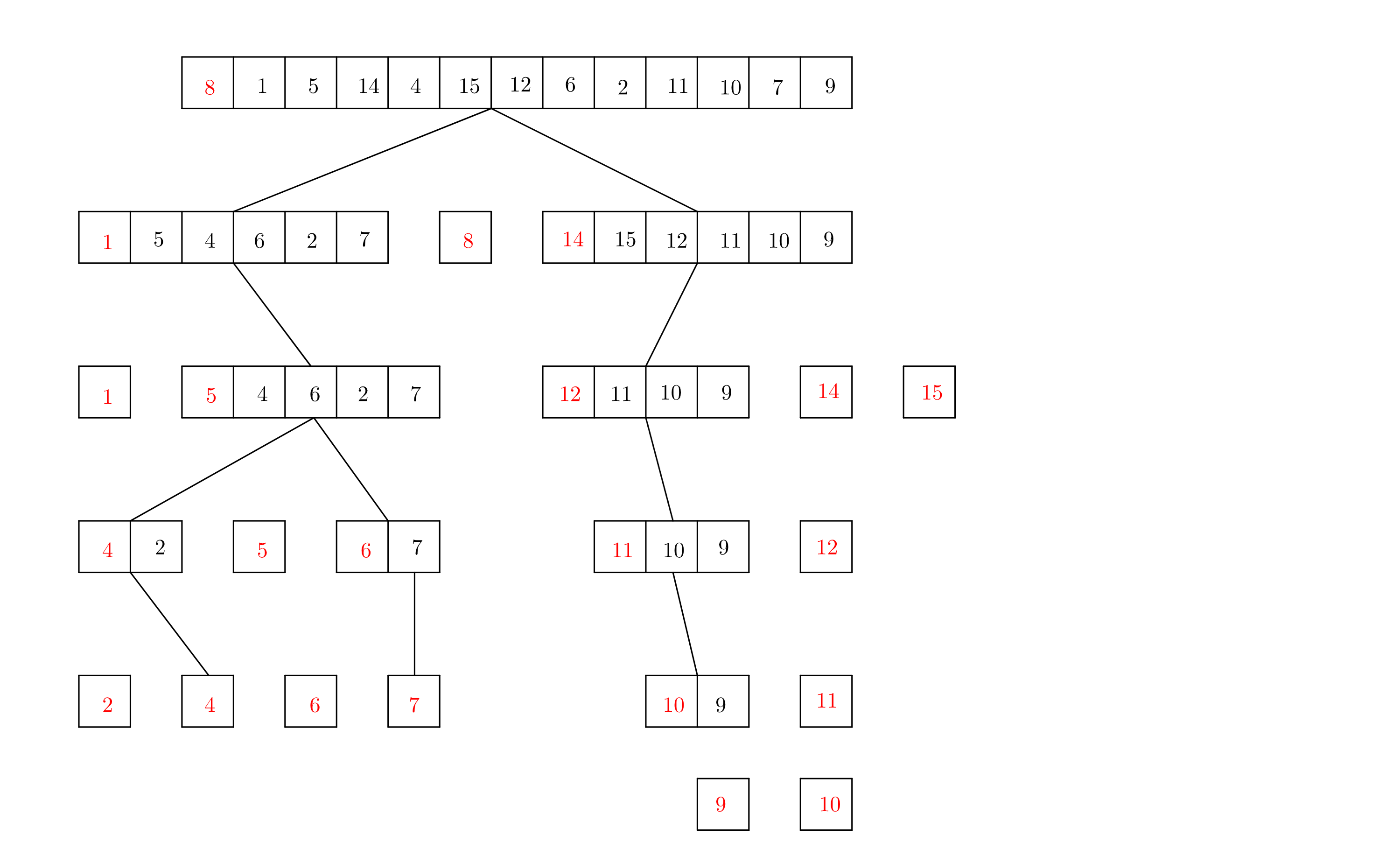
Une fois la liste découpée en sous-listes de taille $1$ dans la pile d'appels, les morceaux sont recollés dans le bon ordre pour avoir un tri de la liste initiale.
Q3. Compléter le code suivant:
def TriRapideRecursif(L):
if len(L) <= 1: # close d'arrêt
return L
else:
pivot = .........
Linf = []
Lsup = []
for x in ......... : # on parcourt une liste mais laquelle ?
if ......... :
Linf.append(x)
else:
Lsup.append(x)
return .................. + ......... + .................. # appels récursifs
# Cellule pour tester
L = [3, 5, 2, 6, 4, 1, 8]
L2 = TriRapideRecursif(L)
print(L2)
On note ${\tt c_n}$ le nombre de comparaisons effectués par l'algorithme récursif dans le pire des cas, pour une liste de taille ${\tt n}$.
Q4. Justifier que ${\tt c_{n}\leq c_{n-1}+n-1}$. En déduire que ${\tt c_n=O(n^2)}$.
C'est encore une complexité quadratique. En théorie ce n'est donc pas mieux que le tri par sélection.
On va évaluer empiriquement la vitesse des deux fonctions précédentes.
Q5. Comprendre puis exécuter les instructions suivantes.
from matplotlib.pyplot import plot, clf, show, legend, figure
from random import randint
from time import time
figure() # on crée une nouvelle figure
X = [] # abscisses
Y = [] # ordonnées
Y2 = [] # ordonnées
for k in range(10,210,10): # k va de 10 à 200 par pas de 10
X.append(k)
L = [ randint( -100000, 10000) for i in range(k) ] # liste aléatoire de k entiers
LL = L[:] # copie de L dans LL ( pourquoi LL = L ne fonctionne pas ?? )
debut = time()
TriSelectionRecursif(L)
fin = time()
duree = fin - debut
Y.append(duree)
debut = time()
TriRapideRecursif(LL)
fin = time()
duree = fin - debut
Y2.append(duree)
plot(X, Y, label='tri selection', marker='+', markersize=10, linewidth=2, color ='r')
plot(X, Y2, label='tri rapide', marker='+', markersize=10, linewidth=2, color ='g')
legend()
show()
Nous allons encore créer un programme récursif utilisant la méthode « diviser pour régner ».
Pour le tri rapide, l’idée était de faire en sorte que les deux parties à concaténer donnent directement le tableau trié, le défaut étant qu’on ne coupe pas toujours en deux parties égales (d'où la complexité en ${\tt O(n^2)}$).
Pour le tri fusion, le principe est différent. On coupe le tableau en deux morceaux toujours égaux, qu’on trie, puis reste l’étape délicate appelée fusion: elle consiste à fusionner ces deux tableaux triés en un tableau encore trié (ce n'est donc plus une simple concaténation).
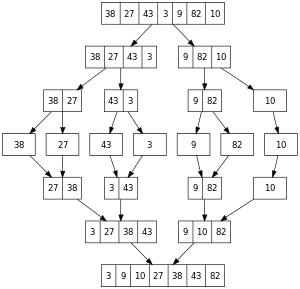
La fonction principale est la fonction ${\tt fusion}$ qui permet de « fusionner » deux tableaux triés en un tableau trié. Pour cela on procède manière récursive : le plus petit élément des deux tableaux est placé en première position du nouveau tableau, il reste ensuite à fusionner les deux tableaux privés de cet élément.
Noter que comme les deux tableaux sont triés, leur plus petit élément est en première position, il n'y a donc pas besoin de le rechercher dans tout le tableau.
Q6. Compléter le code suivant:
def Fusion(L1, L2):
if len(L1) == 0:
return .........
elif len(L2) == 0:
return .........
else:
if ......... :
return ..................
else:
return ..................
# Cellule pour tester
L1 = [2,4,6,8]
L2 = [1,3,5,7]
L3 = Fusion(L1,L2)
print(L3)
Pour trier une liste ${\tt L}$ de taille ${\tt n = len(L)}$ on va donc trier récursivement ses deux moitiés ${\tt L[:n//2]}$ et ${\tt L[n//2:]}$ puis les fusionner.
Q7. En utilisant la fonction ${\tt Fusion(L1,L2)}$ écrire une fonction récursive ${\tt TriRapideRécursif(L)}$ qui renvoie une version triée de la liste ${\tt L}$.
def TriFusionRecursif(L):
if len(L) <= 1:
return .........
else:
n = len(L)
return ..................
# Cellule pour tester:
L = [38, 27, 43, 3, 9, 82, 10]
L2 = TriFusionRecursif(L)
print(L2)
Si on note ${\tt c_n}$ la complexité de l'algorithme récursif dans le pire des cas, pour une liste de taille ${\tt n}$, on a ${\tt c_n\leq 2c_{\lfloor n/2\rfloor}}$ et on peut montrer que ${\tt c_n=O\big(n\ln(n)\big)}$.
C'est cette fois une complexité quasi-linéaire. En théorie c'est donc le meilleur algorithme de tri.
Pour le confirmer ou l'infirmer, on compare empiriquement les trois algorithmes.
Q8. Comprendre puis exécuter les instructions suivantes. Commenter les trois courbes obtenues.
from matplotlib.pyplot import plot, clf, show, legend, figure
from random import randint
from time import time
figure() # on crée une nouvelle figure
X = [] # abscisses
Y = [] # ordonnées
Y2 = [] # ordonnées
Y3 = [] # ordonnées
for k in range(10,510,10): # k va de 10 à 500 par pas de 10
X.append(k)
L = [ randint( -100000, 10000) for i in range(k) ] # liste aléatoire de k entiers
LL = L[:] # copie de L dans LL ( pourquoi LL = L ne fonctionne pas ?? )
LLL = L[:] # copie de L dans LLL
debut = time()
TriSelectionRecursif(L)
fin = time()
duree = fin - debut
Y.append(duree)
debut = time()
TriRapideRecursif(LL)
fin = time()
duree = fin - debut
Y2.append(duree)
debut = time()
TriFusionRecursif(LLL)
fin = time()
duree = fin - debut
Y3.append(duree)
plot(X, Y, label='tri selection', marker='+', markersize=10, linewidth=2, color ='r')
plot(X, Y2, label='tri rapide', marker='+', markersize=10, linewidth=2, color ='g')
plot(X, Y3, label='tri fusion', marker='+', markersize=10, linewidth=2, color ='b')
legend()
show()
On constate la complexité quasi-linéaire du tri fusion, il est bien plus rapide que le tri par insertion.
Par contre il n'est pas aussi efficace que le tri rapide, ce qui contredit nos résultats théoriques. Ceci est du au fait que nous avons estimé la complexité dans le pire de cas, qui ne correspond pas forcement aux cas utilisés en pratique. De plus nous avons seulement compté les comparaisons, sans prendre en compte les nombreuses opérations effectués sur les listes. Nos calculs de complexité sont donc approximatifs.
On définit de manière récursive la structure d'arbre binaire d'entiers. Un arbre binaire d'entiers est :
- soit vide, noté $\emptyset$;
- soit un triplet $(a,g,d)$ où $a$ est un nombre entier et $g$ et $d$ sont des arbres binaires d'entiers.
Si $(a, g, d)$ est un arbre binaire d'entiers, $a$ est appelé sa racine, $g$ son sous-arbre gauche et $d$ son sous-arbre droit. On nomme également fils gauche (resp. droit) de $a$ la racine de $g$ (resp. la racine de $d$).
Les arbres binaires d'entiers sont représentés graphiquement avec la racine en haut et les fils en bas.
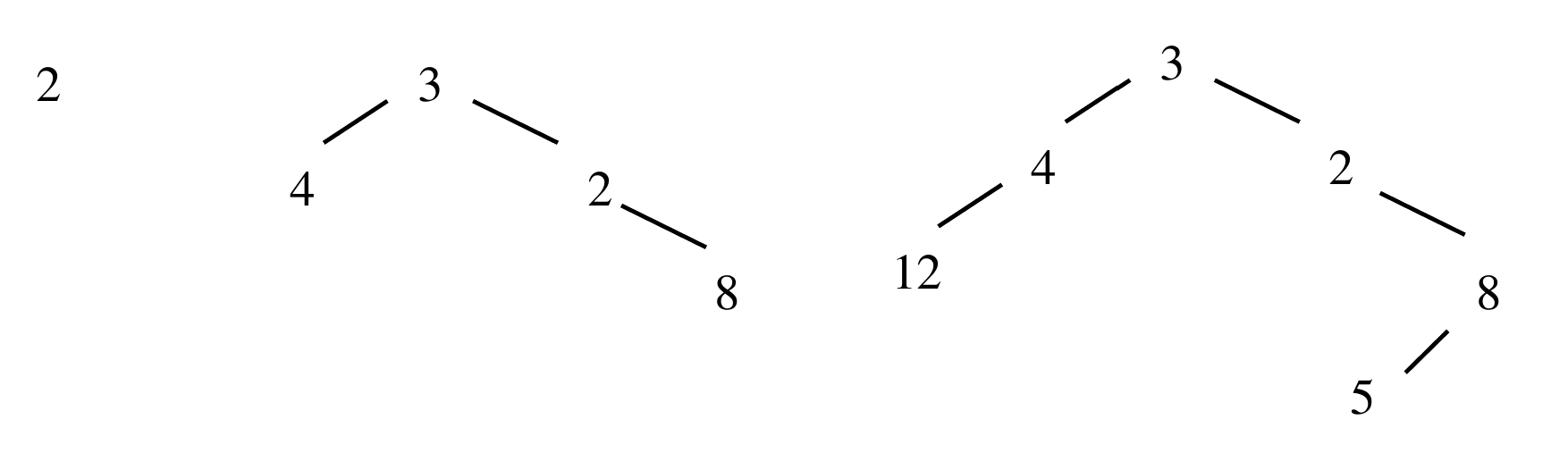
Voici par exemple la représentation graphique des arbres binaires d'entiers $(2,\emptyset,\emptyset)$, $\;\Big(3,(4,\emptyset,\emptyset),\big(2,\emptyset,(8,\emptyset,\emptyset)\big)\Big)$ et $\Big(2, \emptyset, \big(8, (5, \emptyset, \emptyset), \emptyset)\big)\Big)$.
Soient $a$ et $b$ deux entiers.
Si $b$ est le fils de $a$, on appelle $a$ le père de $b$.
De même, on définit la notion de descendant et d’ascendant: $b$ est le descendant de $a$ si $b$ est soit le fils de $a$, soit le fils d'un descendant de $a$; on dit alors que $a$ est un ascendant de $b$.
La racine et ses descendants sont appelés les nœuds de l’arbre. Une feuille est un nœud qui n’a pas de descendant.
Par exemple sur les trois arbres binaires représentés ci-dessus les feuilles sont respectivement:
- $2$
- $4$ et $8$
- $12$ et $5$
La taille d’un arbre binaire d'entiers est son nombre de nœuds, on la définit récursivement par :
- taille($\emptyset$) = 0
- taille($(a, g, d)$) = 1 + taille($g$) + taille($d$)
Sur les trois exemples précédents les tailles respectives sont $1$, $4$ et $6$.
La hauteur d’un arbre binaire d'entiers est défini récursivement par :
- hauteur($\emptyset$) = 0
- hauteur($(a, g, d)$) = 1 + max(hauteur($g$), hauteur($d$))
Sur les trois exemples précédents les hauteurs respectives sont $1$, $3$ et $4$.
On appelle niveau d'un arbre binaire d'entiers l'ensemble des noeuds qui sont à la même hauteur.
On peut démontrer que la hauteur et la taille d’un arbre binaire d'entiers $A$ sont liés par la propriété suivante : $$\Big\lfloor\log_2 (\hbox{taille}(A))\Big\rfloor + 1 \leq \hbox{hauteur}(A) \leq \hbox{taille}(A)$$
Nous pouvons maintenant donner la définition d'un tas (heap en anglais):
- un arbre binaire d'entiers partiellement ordonné est un arbre binaire d'entiers dont les nœuds sont inférieurs ou égaux à leurs fils;
- un arbre binaire d'entiers parfait est un arbre binaire d'entiers dont toutes les feuilles sont situées sur deux niveaux seulement, l’avant-dernier niveau étant complet (tous les noeuds ont deux fils) et les feuilles du dernier niveau étant regroupées le plus à gauche possible;
- un tas est un arbre binaire d'entiers parfait et partiellement ordonné.
Remarquons que dans un tas les noeuds d'un même niveau sont tous inférieurs à ceux du niveau suivant. La racine correspond donc au minimum du tas.
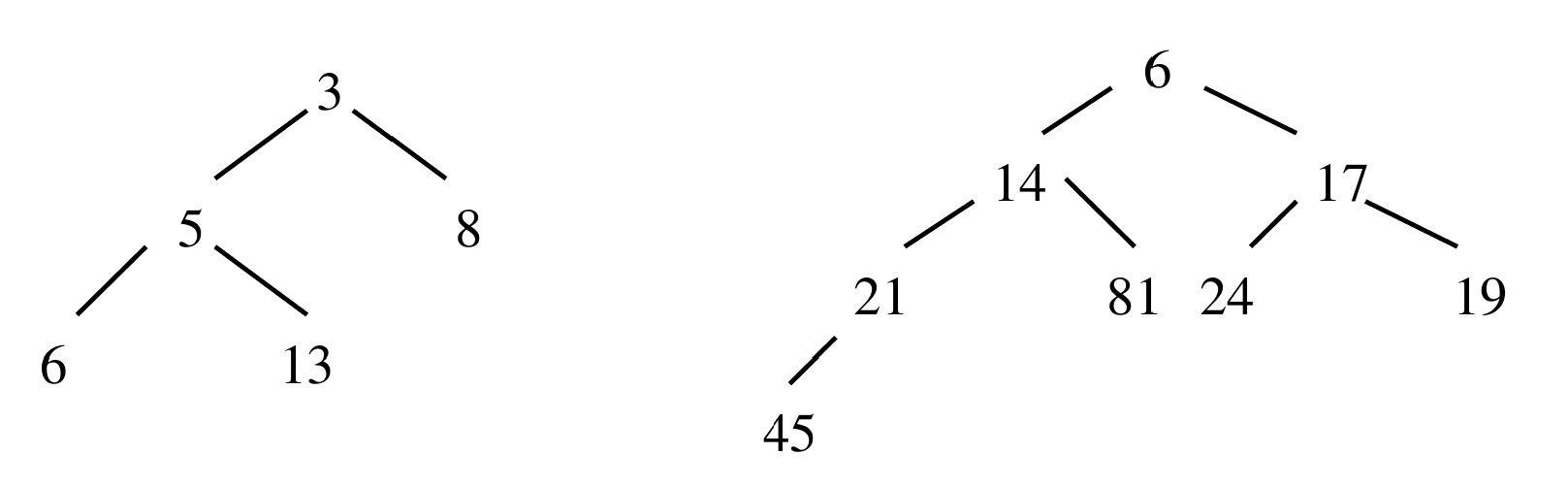
Voici deux exemples de tas.
Voici deux arbres binaires d'entiers qui en sont pas des tas.
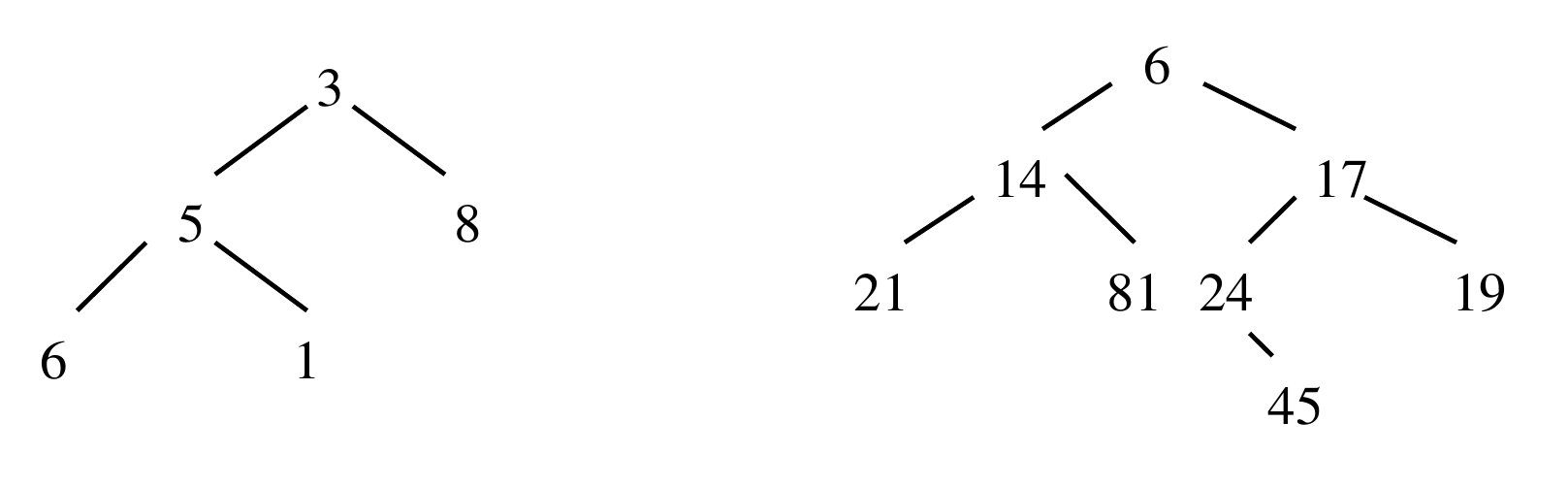
En effet, dans celui de gauche le nœud $1$ est le fils du nœud $5$ donc il n’est pas partiellement ordonné. Dans l’arbre de droite, $24$ a un fils alors que $81$ qui est plus à gauche sur le même niveau n’en a pas. Il n’est donc pas parfait.
On peut démontrer que si un arbre binaire d'entiers $A$ est parfait (en particulier si $A$ est un tas) alors: $$\Big\lfloor\log_2 (\hbox{taille}(A))\Big\rfloor + 1 = \hbox{hauteur}(A) $$
5.2 Tri par tas¶
On définit deux opérations sur les tas. La première consiste à ajouter un noeud. On procède ainsi: possible de façon à maintenir l’arbre parfait;
- on rajoute une feuille au dernier niveau de l’arbre (ou au niveau suivant si le dernier niveau est complet) le plus à gauche
- l’arbre obtenu n’est plus forcément partiellement ordonné, dans ce cas on échange la nouvelle feuille avec son père s’il est plus grand, puis le père avec le nœud au dessus s’il est plus grand, ... jusqu’à ce que la propriété soit rétablie.
Par exemple avec le tas:
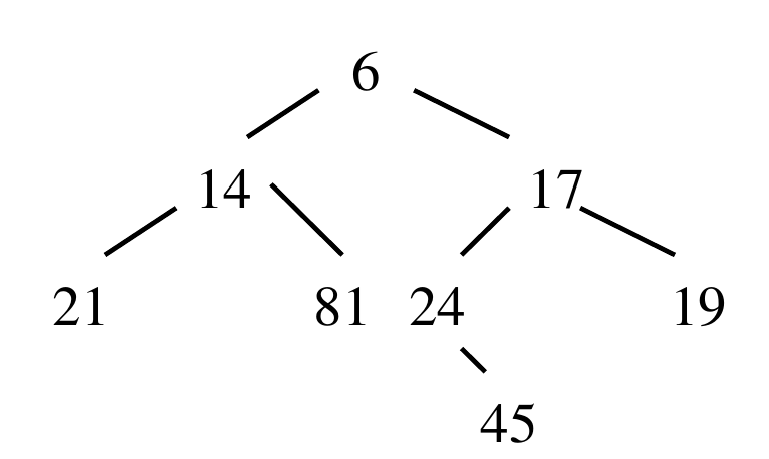
On ajoute le noeud $10$:
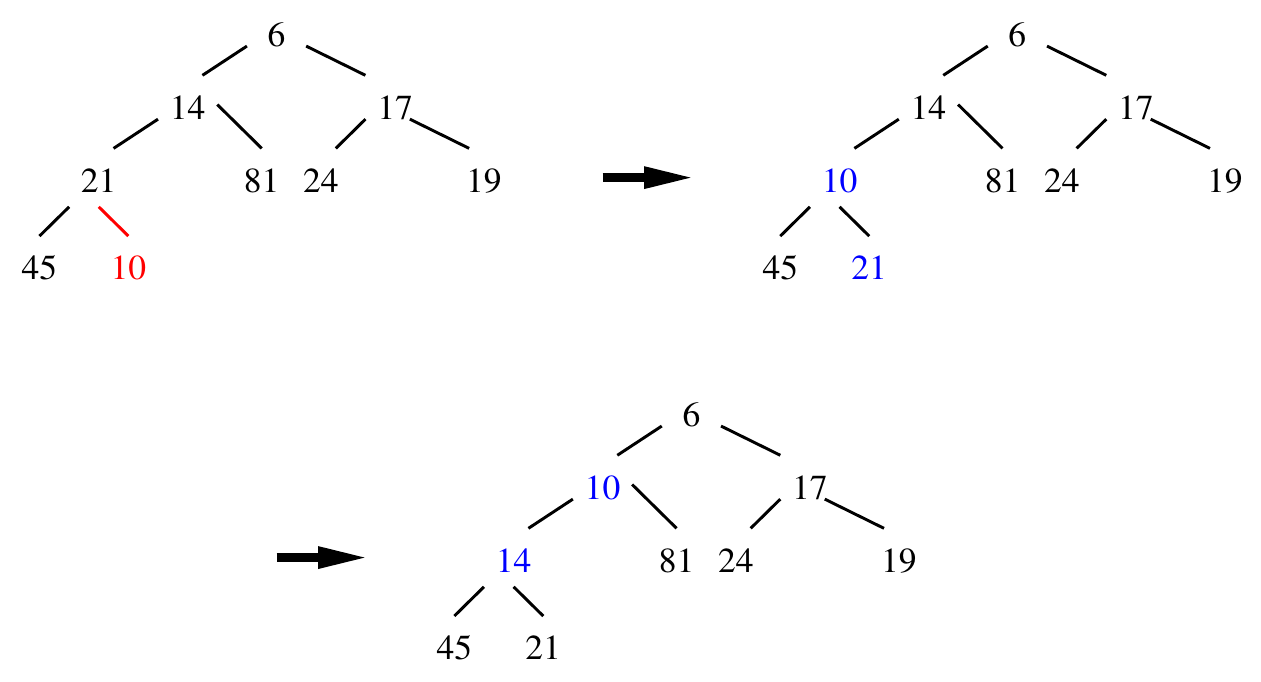
On commence par placer $10$ dans la feuille vacante tout en bas à gauche. Comme $21$ le père de $10$ est plus grand, on échange $10$ et $21$. On regarde au dessus, $10$ et $14$ ne sont pas dans le bon ordre, donc on les échange également. $10$ et $6$ sont ordonnés correctement donc on a fini.
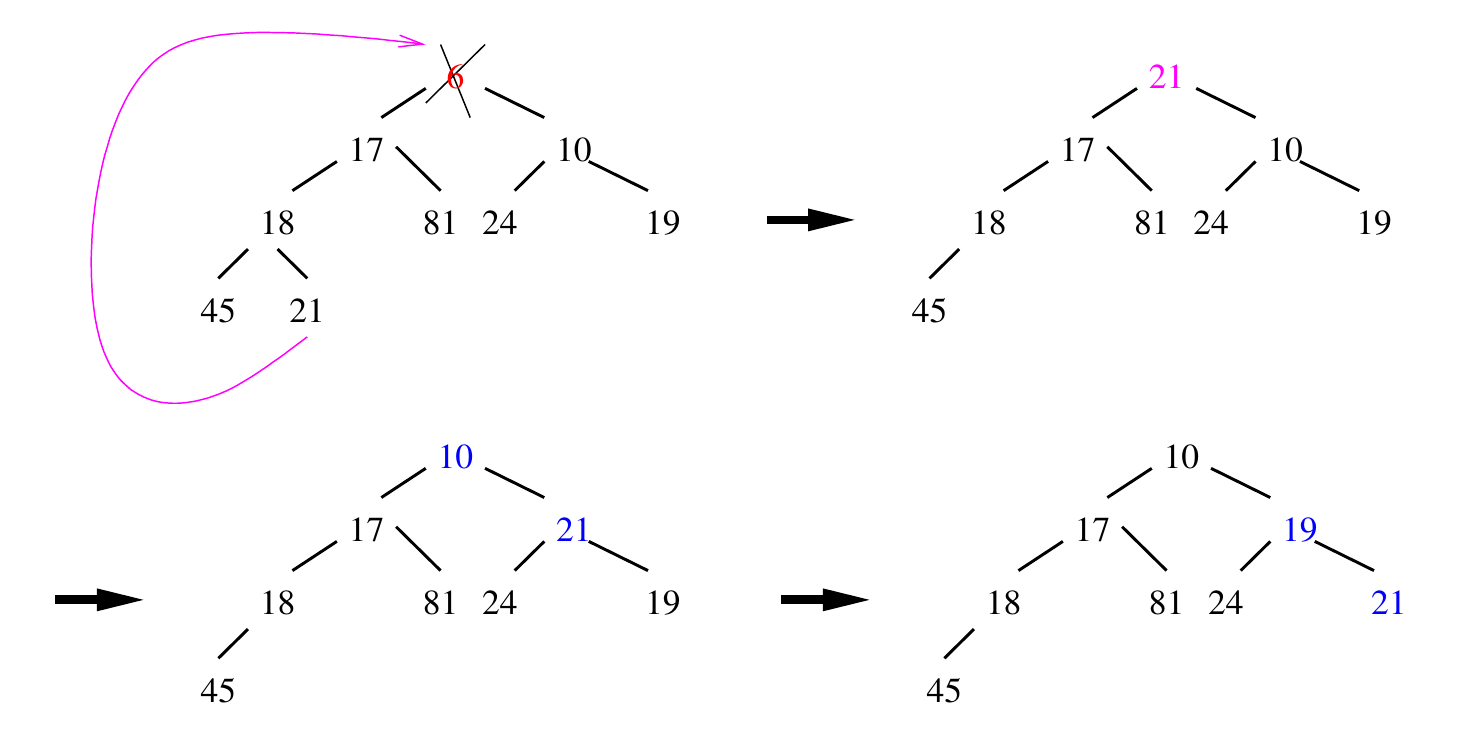
L'opération suivante consiste à supprimer la racine du tas, c'est-à-dire son élément minimum: maintient ainsi l’arbre parfait mais il peut perdre la propriété d’ordre partiel;
- on commence par remplacer cette racine par la feuille la plus en bas à droite;
- on
- pour la rétablir on va échanger la racine avec le plus petit de ses fils (si l’un d’entre eux est plus petit qu’elle), puis recommencer avec le fils échangé, ainsi de suite jusqu’à ce que l’arbre soit à nouveau partiellement ordonné.
Par exemple avec le tas précédent:
Le tri par tas d'une liste d'netiers L se fait alors de la manière suivante:
- on initialise un tas
Tvide et une listeL2vide; - on parcourt
Lde gauche à droite et on ajoute l'élément courant au tasT; - ensuite on enlève la racine du tas
Tqu'on ajoute à droite de la listeL2, et on recommence jusqu'à ce queTsoit le tas vide.
On peut montrer que dans le pire des cas le nombre de comparaisons effectués par cet algorithme est en $O(n\ln(n))$ avec n=len(L). Il est donc quasi-linéaire. Par contre il ne se fait pas en place.
Q9. Utiliser à la main l'algorithme du tri par tas pour trier la liste L = [10, 11, 3, 6, 4, 2].
Le module heapq propose une implémentation Python de la structure de tas.
Pour créer un tas vide on utilise l'instruction tas = [].
Pour ajouter l'élément x au tas tas on utilise l'instruction heappush(tas, x).
Pour supprimer la racine du tas tas et enregistrer sa valeur dans une variable y on utilise l'instruction y = heappop(tas, x).
Q10. Proposer une fonction triTas(L) qui trie la liste L dans l'ordre croissant en utilisant le tri par tas et le module heapq.
Cette fonction renvoie une version triée de L.
# Cellule à compléter
from heapq import *
def triTas(L) :
On teste:
# Cellule pour tester
L = [10, 11, 3, 6, 4, 2]
L2 = triTas(L)
print(L2)
Q11. Ajouter le tri par tas aux courbes de la question Q8..
# Cellule à compléter
Q12. On donne la fonction hprint(tas) qui permet d'afficher un tas.
Modifier votre fonction triTas(L) pour qu'elle affiche le tas au fur et à mesure du tri.
# Cellule à compléter
from math import log
first = lambda h: 2**h - 1 # H stands for level height
last = lambda h: first(h + 1)
level = lambda heap, h: heap[first(h):last(h)]
prepare = lambda e, field: str(e).center(field)
def hprint(heap) :
if len(heap) != 0 :
width = max(len(str(e)) for e in heap)
height = int(log(len(heap), 2)) + 1
gap = ' ' * width
for h in range(height):
below = 2 ** (height - h - 1)
field = (2 * below - 1) * width
print(gap.join(prepare(e, field) for e in level(heap, h)))
print('\n')
print('\n')
def triTas2(L) :
On teste:
# Cellule pour tester
L = [10, 11, 3, 6, 4, 2]
L2 = triTas2(L)
Implémenter le tri par tas en Python en utilisant uniquement la structure de liste et de telle sorte que le tri soit fait en place.