On considère dans la suite du TP des graphes non-orientés.
Pour tester les fonctions, on pourra utiliser le graphe suivant:
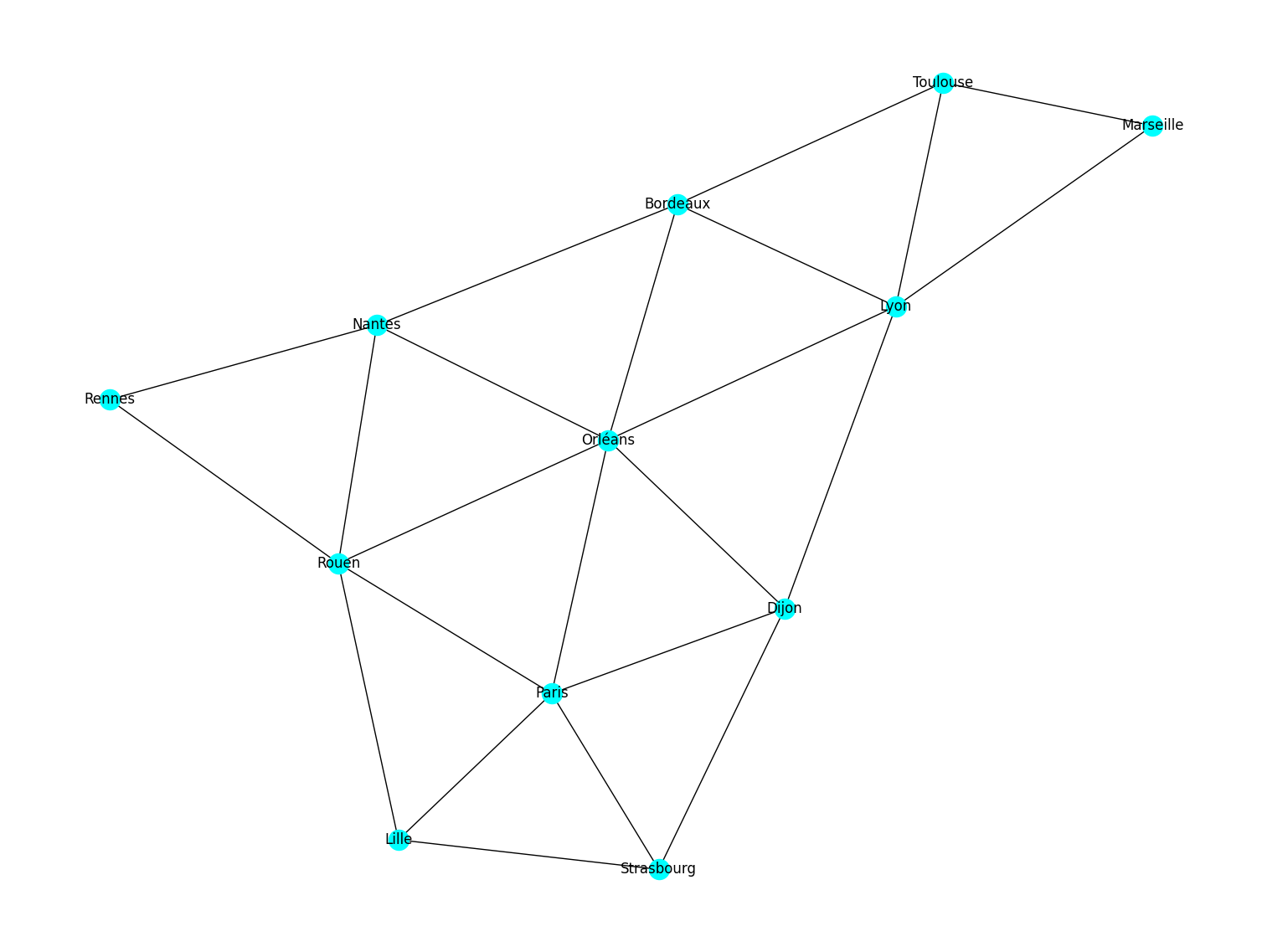
On considère dans la suite du TP des graphes non-orientés.
Pour tester les fonctions, on pourra utiliser le graphe suivant:
On l'implémente en Python de la manière suivante:
# on numérote les sommets: sommets[k] donne le nom du sommet numéro k
sommets = ["Rennes","Nantes","Rouen","Lille","Paris","Strasbourg","Orléans","Dijon","Bordeaux",\
"Toulouse","Lyon","Marseille"]
# on crée la liste d'adjacence
Lvilles = [ [1, 2], [0, 2, 6, 8], [0, 1, 3, 4, 6], [2, 4, 5], [2, 3, 5, 6, 7], [3, 4, 7], [1, 2, 4, 7, 8, 10],\
[4, 5, 6, 10], [1, 6, 9, 10], [8, 10, 11], [6, 7, 8, 9, 11], [9, 10] ]
Le parcours d’un graphe consiste à visiter (une et une seule fois) chaque sommet du graphe afin de résoudre un problème donné. Contrairement au parcours de liste dont nous avons l’habitude, qui est naturellement linéaire (ie de gauche à droite ou de droite à gauche), le parcours de graphe impose, de par la structure du graphe, de faire des choix dans l’ordre de visite des sommets.
Une première possibilité consiste à parcourir le graphe en profondeur, c’est-à-dire à marquer le sommet où l’on se trouve, puis à visiter un sommet voisin non marqué s’il en existe ; sinon, on revient au sommet précédent.
Visiter les sommets consiste ici à les ajouter à une pile. Une pile (stack en anglais) est une structure de données linéaire qui se distingue par ses conditions d’accès et d’ajout d’éléments : c’est le principe du « dernier arrivé, premier sorti » (principe du LIFO pour Last In, First Out). Un peu comme une pile d’assiettes, c’est la dernière assiette posée sur une pile qui sera la première utilisée.
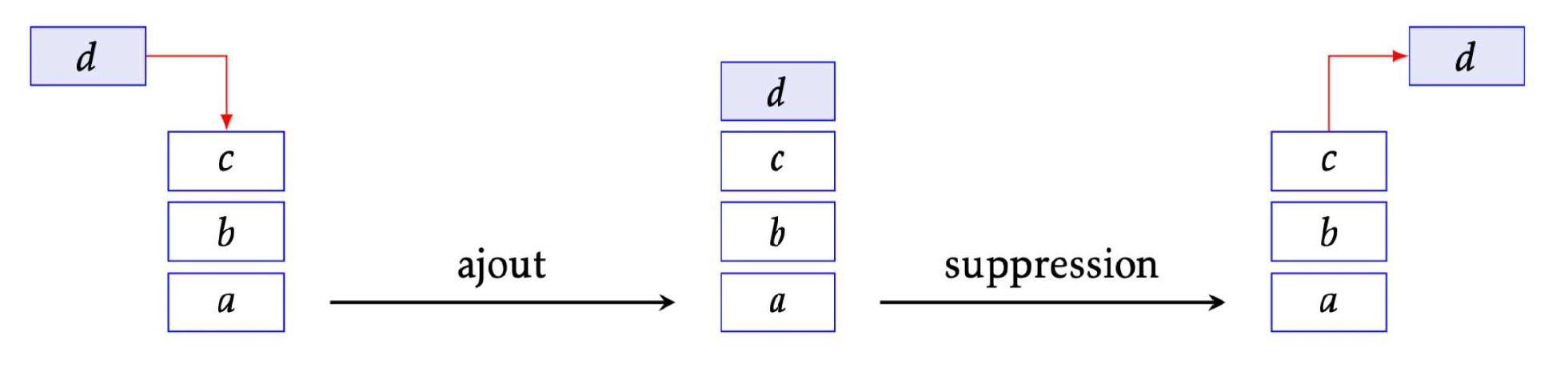
Une réalisation concrète de cette structure de données fournit, outre la structure, les fonctions suivantes :
En Python lorsqu’on aura besoin d’une pile, on utilisera tout simplement une liste ${\tt L}$ et on se restreindra aux méthodes ${\tt append}$ et ${\tt pop}$ pour empiler et dépiler, ainsi qu'à l’instuction ${\tt L[-1]}$ pour l’accès au dernier élément.
pile = [1, 2, 3]
pile.append(4)
pile
x = pile.pop()
pile
x
Le parcours en profondeur se fait donc ainsi:
- s'il n'est pas marqué alors on le marque, puis parmi tous ses voisins on empile ceux qui ne sont pas encore marqués
- s'il est déjà marqué on ne fait rien
Pour marquer un sommet on utilisera une liste visites telle que visites[k]=True si le sommet numéro k a été visité et visites[k]=False sinon. Initialement tous les éléments de cette liste sont égaux à False.
Au moment de marquer un sommet on peut faire d'autres opérations comme l'afficher pour visualiser comment l'arbre a été parcouru.
Q1. Compléter la fonction parcours_profondeur(L,s) qui prend en arguments la liste d'adjacence L d'un
graphe et s qui est le numéro du sommet de départ, et renvoie la liste des numéros des sommets dans l'ordre de leur marquage selon l'algorithme de parcours en profondeur.
def parcours_profondeur(L, s):
nbSommets = ......
marques = [ False for k in range(nbSommets) ] # marques[k]=True si le sommet k a été marqué
pile = ...... # initialisation de la pile
parcours = ...... # liste qui va stocker les sommets dans l'ordre de leur marquage
while len(pile) != 0:
sommet = ......
if not(marques[sommet]):
marques[sommet] = ......
parcours.append( ...... )
for voisin in L[sommet]:
if not(marques[voisin]):
pile.append( ...... )
else:
continue # facultatif: on ne fait rien
return parcours
# Tests unitaires
Lexemple = [ [1,5,6], [2,3], [1], [1, 4], [3], [0], [0, 7, 8], [6], [6] ]
parcours = parcours_profondeur(Lexemple, 0)
print( parcours == [0, 6, 8, 7, 5, 1, 3, 4, 2] )
parcours = parcours_profondeur(Lvilles, 0)
print( parcours == [0, 2, 6, 10, 11, 9, 8, 1, 7, 5, 4, 3] )
Q2. La liste parcours ci-dessus obtenu pour le graphe représenté par Lvilles donne les numéros des sommets. Ecrire une instruction qui la remplace par une liste parcours qui donne la liste des noms des sommets.
# Cellule à compléter
parcours = ......
print(parcours)
On doit obtenir:
['Rennes', 'Rouen', 'Orléans', 'Lyon', 'Marseille', 'Toulouse', 'Bordeaux', 'Nantes', 'Dijon', 'Strasbourg', 'Paris', 'Lille'].
Une autre possibilité consiste à parcourir le graphe en largeur, c’est-à-dire à marquer le sommet où l’on se trouve, puis à marquer tous ses voisins non encore marqués, puis tous les voisins de ses voisins etc...
La structure de l'algorithme est donc la même que pour l'algorithme de parcours en profondeur mais on remplace la pile par une file.
Une file (queue en anglais) est une structure de données linéaire fonctionnant sur le principe du FIFO (First In, First Out). On peut l’imaginer horizontale : on rajoute des éléments par la droite et on les enlève par la gauche. Cette fois, l’analogie se fait avec une file d’attente. Les clients arrivent par la droite et la caisse est à gauche. Le prochain client servi étant celui qui attend depuis le plus longtemps.

Une réalisation concrète de cette structure de données fournit, outre la structure, les fonctions suivantes :
En Python la structure de liste n’est pas adaptée à la structure de file. En effet si on veut enfiler un élément ( = ajouter un élément à droite ) cela se fait avec append avec une complexité en $O(1)$ mais si on veut défiler un élément ( = supprimer l'élément de gauche ) on doit décaler un par un par un vers la gauche tous les éléments de la liste ce qui donne une complexité en $O(n)$.
On utilisera plutôt une
« double ended queue » ou « deque » telle qu’elle est disponible dans le module collections. Toutes les opérations se feront alors en $O(1)$.
import collections
file = collections.deque() # Pour créer une file vide
file = collections.deque([1,2,3]) # Pour créer la file 1,2,3
n = len( file ) # Pour connaitre la longueur de la file
file.append(4) # pour enfiler un élément à droite
x = file.popleft() # Pour défiler un élément à gauche et stocker sa valeur dans x
Du point de vue de l’écriture du code, cela ne change pas grand-chose, mais du point de
vue de la complexité, ça change tout. En effet, l’instruction popleft() est en $O(1)$.
Pour la suite, on utilisera donc des deque pour les files.
Le parcours en largeur se fait donc ainsi (remarquer l'analogie avec le parcours en profondeur):
- s'il n'est pas marqué alors on le marque, puis parmi tous ses voisins on emfile ceux qui ne sont pas encore marqués
- s'il est déjà marqué on ne fait rien
Q3. Ecrire une fonction parcours_largeur(L,s) qui prend en arguments la liste d'adjacence L d'un
graphe et s qui est le numéro du sommet de départ, et renvoie la liste des numéros des sommets dans l'ordre de leur marquage selon l'algorithme de parcours en largeur
# Copier/Coller la fonction de parcours en profondeur puis la modifier
import collections
def parcours_largeur(L, s):
# Test unitaires
Lexemple = [ [1,5,6], [2,3], [1], [1, 4], [3], [0], [0, 7, 8], [6], [6] ]
parcours = parcours_largeur(Lexemple,0)
print( parcours == [0, 1, 5, 6, 2, 3, 7, 8, 4] )
parcours = parcours_largeur(Lvilles,0)
print( parcours == [0, 1, 2, 6, 8, 3, 4, 7, 10, 9, 5, 11] )
Q4. La liste parcours ci-dessus obtenu pour le graphe représenté par Lvilles donne les numéros des sommets. Ecrire une instruction qui la remplace par une liste parcours qui donne la liste des noms des sommets.
# Cellule à compléter
parcours = [ sommets[k] for k in parcours ]
print(parcours)
On doit obtenir:
['Rennes', 'Nantes', 'Rouen', 'Orléans', 'Bordeaux', 'Lille', 'Paris', 'Dijon', 'Lyon', 'Toulouse', 'Strasbourg', 'Marseille'].
La coloration d’un graphe consiste à colorier les sommets d’un graphe, de sorte que deux sommets voisins n’aient jamais la même couleur, en utilisant au total un minimum de couleurs.
Pour obtenir une coloration proche de l’optimale, on utilise l’algorithme de Welsh-Powell:
de leurs voisins)
une nouvelle couleur, qu’on attribue au premier sommet non-coloré ainsi qu’à tous les autres sommets non-colorés qui ne sont pas voisins d’un sommet de cette couleur.
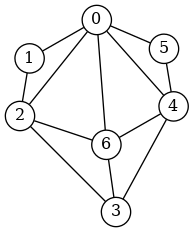
Q5. Appliquer cet algorithme, à la main, au graphe suivant :
Q6. Écrire une fonction degre(L,k) qui prend en argument une liste d'adjacence L et un sommet k
et renvoie le degré du sommet k.
# Cellule à compléter
def degre(L,k):
# Tests unitaires
Lexemple2 = [ [1, 2, 4, 5, 6], [0, 2], [0, 1, 3, 6], [2, 4, 6], [0, 3, 5, 6], [0, 4], [0, 2, 3 ,4] ]
print( degre(Lexemple2, 6) == 4 )
print( degre(Lvilles, 6) == 6 )
# Tests libres
Q7. Écrire une fonction trier(L) qui renvoie la liste des numéros des sommets du graphe, triés dans
l’ordre des degrés décroissants.
On pourra pour cela modifier la fonction suivante qui effectue un tri croissant par insertion sur une `liste:
def tri_insertion(liste):
for i in range(1,len(liste)):
en_cours = liste[i]
j = i
#décalage des éléments du tableau (qui est déjà trié sur les j premiers éléments)
while j > 0 and liste[j-1] > en_cours:
liste[j] = liste[j-1]
j = j-1
#on insère l'élément à sa place
liste[j] = en_cours
# Cellule à compléter
def trier(L):
# Tests unitaires
print( trier(Lexemple2) == [0, 2, 4, 6, 3, 1, 5] )
print( trier(Lvilles) == [6, 2, 4, 10, 1, 7, 8, 3, 5, 9, 0, 11] )
# Tests libres
Q8. Ecrire une fonction colore_sommet de trois arguments, la liste C des couleurs attribuées, le
numéro s du sommet à colorer et la liste d’adjacence L caractérisant le graphe.
Cette fonction ne renvoie rien mais modifie la liste C en donnant à C[s] la plus petite couleur
possible, en fonction des couleurs des sommets voisins qui sont déjà colorés.
Par exemple pour le graphe à $7$ sommets suivants: `
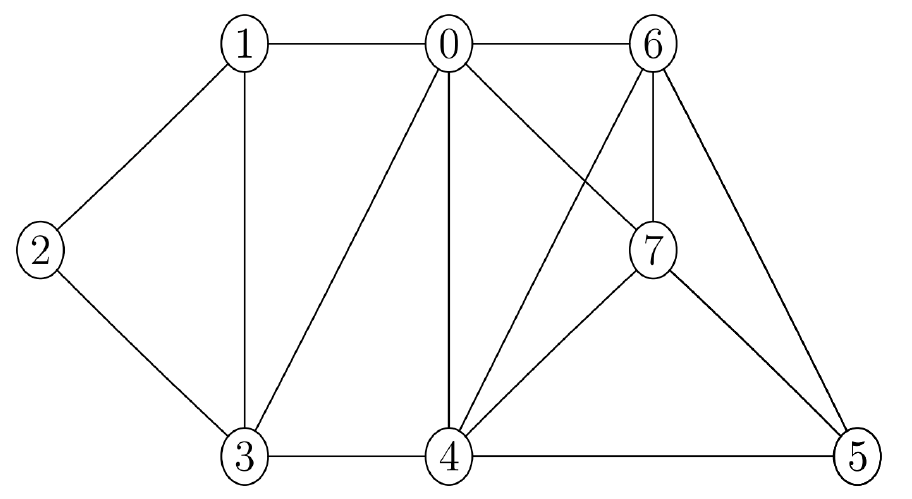
prenons C = [0, 1, -1, -1, -1, -1, -1, -1]. Les sommets 0 et 1
ont donc déjà été colorés avec les couleurs C[0]=0 et C[1]=1, et les autres n'ont pas encore été colorés (ce sont les valeurs $-1$).
L’appel colore_sommet(C, 2, L) modifie la liste C en C=[0, 1, 0, -1, -1, -1, -1, -1]. Cela veut
dire que la couleur 0 a été attribuée au sommet 2 (on rappelle qu'on veut utiliser un minimum de couleurs).
# cellule à compléter
def colore_sommet(C, s, L):
# Test unitaires
# exécuter cette cellule pour tester avec l'exemple précédent:
LA = [[1, 3, 4, 6, 7], [0, 2, 3], [1, 3], [0, 1, 2, 4], [0, 3, 5, 6, 7], [4, 6, 7], [0, 4, 5, 7], [0, 4, 5, 6]]
C = [0, 1, -1, -1, -1, -1, -1, -1]
colore_sommet(C, 2, LA)
print( C == [0, 1, 0, -1, -1, -1, -1, -1] )
# Tests libres
Q9. Écrire une fonction colorer(L) qui met en œuvre l’algorithme de Welsh-Powell, et
renvoie la liste des couples (sommet,couleur).
# Cellule à compléter
def colorer(L):
# Tests unitaires
print( colorer(Lexemple2) == [(0, 0), (1, 2), (2, 1), (3, 0), (4, 1), (5, 2), (6, 2)] )
print( colorer(Lvilles) == [(0, 0), (1, 2), (2, 1), (3, 0), (4, 2), (5, 1), (6, 0), (7, 3), (8, 3), (9, 0), (10, 1), (11, 2)] )
# Tests libres
On modélise un labyrinthe de taille m × n à l’aide d’un graphe de la façon suivante:
0 à mn - 1 (de gauche à droite puisde haut en bas) et constituent les sommets du graphe,
sont pas séparées par un mur), on met une arête entre les sommets correspondants.
Q10. Implémenter la liste d'adjacence du graphe correspondant au labyrinthe suivant:

# Cellule à compléter
lab = [ [1], [0, 5], [6], [7], [5, 8], [4, 1], [2, 7, 10], [3, 6, 11], [4, 9], [8, 10], [6, 9], [7] ]
C'est le graphe:

Q11. Écrire une fonction sortir(L,s,sortie) qui prend en argument la liste d'adjacence L représentant le labyrinthe, une case s du labyrinthe, la case sortie de sortie du labytinthe
et qui renvoie une liste parcours de sommets permettant de sortir du labyrinthe (c'est-à-dire d'arriver à la case sortie) à
partir de la case s. On utilisera le parcours en profondeur, en prenant soin, dans
la liste parcours, d’enlever les pistes menant à une impasse lorsqu’on doit rebrousser
chemin. Pour cela on ajoutera une liste peres telle que peres[k] donne l'antécédent du sommet k dans le parcours (on initialisera à $-1$ tant que l'antécédent n'est pas connu).
# copier/coller la fonction parcours_profondeur puis la modifier
def sortir(L,s,sortie):
# Cellule pour tester
sortir(lab,11,3)