
La longueur d'une liste ${\tt L}$ est obtenue avec ${\tt len(L)}$. Si la liste a ${\tt n=len(L)}$ éléments, ils sont indexés de ${\tt 0}$ à ${\tt n-1}$.
L = [1, 2, 3, 4, 5]
len(L) # longueur de la liste
5
L[0] # premier élément de la liste
1
L[4] # dernier élément d'une liste de taille 5
5
L[5] # il n'y a pas de 6-ième élément
--------------------------------------------------------------------------- IndexError Traceback (most recent call last) Cell In[5], line 1 ----> 1 L[5] IndexError: list index out of range
L[1:4] # éléments d'indice 1 inclus à 4 exclus
[3, 4]
L[1:] # tous les éléments sauf le premier
[2, 3, 4, 5]
L[:-1] # tous les éléments sauf le dernier
[1, 2, 3, 4]
On concatène les listes avec ${\tt +}$ et on ajoute un élément ${\tt }$ avec l'instruction ${\tt L.append(x)}$.
L = L + [6, 7, 8] # on concatène
L
[1, 2, 3, 4, 5, 6, 7, 8]
L = [1, 2, 3, 4, 5]
L.append([6,7,8]) # ne donne pas d'erreur
L # ce n'est pas du tout ce qu'on voulait faire !!
[1, 2, 3, 4, 5, [6, 7, 8]]
L = [1, 2, 3, 4, 5, 6, 7, 8]
L.append(9)
L # là tout va bien
[1, 2, 3, 4, 5, 6, 7, 8, 9]
On veut mettre le dernier élément en première position:
[ L[-1] ] + L[:-1] # à gauche de + on a une liste avec un seul élément
[9, 1, 2, 3, 4, 5, 6, 7, 8]
Lorsqu'on donne une variable de type nombre (${\tt int}$ ou ${\tt float}$) en entrée d'une fonction une copie de cette variable est utilisée par la fonction.
def f(x):
x = x + 1
return x
x = 2
f(x)
3
x # x n'a pas été modifiée !!
2
${\tt x}$ n'a pas été modifiée: c'est sa copie qui l'a été. La fonction ne récupère donc que la valeur de la variable ${\tt x}$. On dit que la variable a été donnée en argument par valeur (la fonction ne connaît que la valeur de la variable).
Lorsque la variable est du type liste (${\tt list}$) le comportement de Python est différent: effectuer une copie de la liste a été jugé trop coûteux en mémoire (choix des concepteurs de Python), la fonction récupère donc la variable d'origine. Elle est donc capable de la modifier. On dit que la variable a été donnée en argument par adresse (la fonction connaît l'adresse mémoire de la variable et peut donc y écrire une autre valeur).
def g(L):
L[0] = L[0] + 1 # on ajoute 1 au premier élément
return L
L = [1, 1, 1]
g(L)
[2, 1, 1]
L # L a été modifiée !!
[2, 1, 1]
On n'a donc pas besoin de renvoyer une valeur en sortie (avec ${\tt return}$) puisqu'on modifie la variable d'entrée.
def g(L):
L[0] = L[0] + 1 # fonction sans return
# ( en fait Python rajoute return None )
L = [1, 1, 1]
g(L)
L
[2, 1, 1]
L = g(L) # NE PAS ECRIRE CELA
print(L) # voici pourquoi
None
Dans les fonctions de tri, on pourra donc trier directement la liste donnée en entrée, sans utiliser de copie.
L’objectif des prochaines séquences est:
1 - D’étudier quelques algorithmes de tri qui s’appliquent à des tableaux ou à des listes, tris quadratiques dans un premier temps puis quasi-linéaire dans un second temps.
2 - D’estimer leur coût calculatoire afin de mener une approche comparative.
Le concept de coût associé à un algorithme formalise la notion intuitive d’efficacité d’un programme, c’est à dire sa capacité à fournir le résultat escompté dans un temps minimal, on parle également de performances du programme. Du point de vue pratique, l’analyse du coût permet de déterminer quelles seront les ressources en temps de calcul, en mémoire et éventuellement en entrées/sorties nécessaires pour exécuter le calcul associé à l’algorithme.
Dans le cadre d’une approche simplifiée et, dans une certaine mesure réductrice, la comparaison des algorithmes de tri se limitera principalement à l’étude de leur complexité temporelle: on essaye d'estimer de manière théorique le temps d'exécution d'un programme. Elle est toutefois difficile à estimer car elle dépend de très nombreux paramètres, non seulement de la dimension de l’objet à traiter mais aussi de la structure des données.
Différents types de complexité temporelle sont pertinents. La seule que nous étudierons est la complexité dans le pire cas : on estime le nombre d’opérations effectués dans un contexte du traitement tel que le nombre d’opérations est systématiquement maximal.
La notion de complexité peut aussi se définir par rapport à la consommation d’espace de l’algorithme (quantité de mémoire occupée). On parle alors de complexité spatiale.
Outre la complexité temporelle de l’algorithme, certaines propriétés sont appréciables parmi lesquelles le caractère en place du tri: dans ce cas, l’algorithme modifie directement la structure qu’il est en train de trier (sans travailler sur une copie). Il ne requiert donc qu’un espace en mémoire constant: le tableau d’entrée qu'on veut trier.
Un algorithme de tri est un algorithme qui permet d’organiser un tableau homogène ${\tt T}$ d’éléments selon un ordre fixé. En général, l'algorithme de tri ne retourne rien: en sortie de fonction, le tableau passé en entrée a été trié.
Ainsi, un algorithme générique de tri possède la propriété fondamentale suivante:
Entrée : Un tableau T dont les éléments sont à valeurs dans un ensemble ordonné.
Sortie : Rien (mais le tableau T a été trié ) (dans l’ordre croissant par exemple)
En pratique, les ordres les plus utilisés sont l’ordre numérique (sur les réels ou les entiers naturels et relatifs) et l’ordre lexicographique (pour traiter des chaînes de caractères ou des n-uplets). Par la suite, on ne se préoccupera pas de la relation d’ordre utilisée, celle-ci sera vue comme une « boite noire », comparant deux éléments quelconques d’un ensemble ${\tt E}$.
On détaille ici les algorithmes de tris « naïfs » les plus classiques. Ceux-ci sont quadratiques et sont donc inefficaces pour de grands tableaux. On leur préférera l’un des algorithmes de la section suivante dès que le nombre d’éléments à trier dépasse quelques centaines.
Ce tri particulièrement simple est probablement la méthode à laquelle on pense lorsqu’on écrit un algorithme de tri.
Principe: supposons que le tableau de taille ${\tt n}$ est déjà en partie trié avec ses ${\tt i}$ premiers éléments à leur place définitive. On sélectionne le plus petit des ${\tt n- i}$ éléments restants, qu’on amène en position ${\tt i + 1}$. Le tableau a alors ses ${\tt i + 1}$ premiers éléments à leur position définitive.
Itérer ce procédé pour ${\tt i\in[[0,n-2]]}$ (donc ${\tt n-1}$ fois) suffit pour trier le tableau.
Principe: supposons que la partition ${\tt T[0: i - 1]}$ du tableau ${\tt T}$ est triée. On s’intéresse à l’élément ${\tt T[i]}$, que l’on va insérer dans les éléments déjà triés de la partition ${\tt T[0: i - 1]}$ de sorte que le tableau ${\tt T[0: i]}$ soit trié.
Pour se faire, à l’itérée ${\tt i}$, la valeur ${\tt T[i]}$ est affectée à une variable ${\tt Mem}$ afin de permettre un décalage à droite des éléments de ${\tt T[0: i - 1]}$ tant qu'ils ont une valeur strictement supérieure à ${\tt Mem}$ (la valeur de ${\tt T[i]}$ a été effacée et remplacée par celle de ${\tt T[i-1]}$, mais elle n'a pas été perdue car sauvegardée dans ${\tt Mem}$).

Complexité: Il suffit de dénombrer séparément les comparaisons et les affectations dans le pire des cas. Le pire des cas signifie que la condition logique de la boucle tant que est toujours vérifiée jusqu’à ${\tt j = 0}$. A chaque itération chaque élément traité est placé en début de liste après un décalage à droite complet de la liste déjà triée. Cette situation correspond à une liste donnée en entrée qui est déjà triée mais par ordre décroissant des valeurs.
Le calcul est détaillé dans le tableau ci-dessus.
On suppose que le tableau a ${\tt n}$ éléments.
L’algorithme parcourt le tableau et compare les couples d’éléments successifs. Lorsque deux éléments successifs ne sont pas dans l’ordre croissant, ils sont échangés. Ainsi, à la fin du premier passage, la plus grande valeur remonte en fin de liste.
Si au moins un échange a eu lieu pendant le parcours, l’algorithme procède à un nouveau traitement mais sur les ${\tt n - 1}$ premiers éléments ce qui fait encore remonter les plus grand élément parmi les ${\tt n-1}$ premiers éléments.
Le tableau est trié et l’algorithme s’arrête lorsqu’il n’y a plus d’échange pendant un parcours.

Q1. Pour chacun des pseudocodes présentés, écrivez les fonctions associées ${\tt triselection(T)}$, ${\tt triinsertion(T)}$ et ${\tt tribulles(T)}$. Ces fonctions ont pour argument d’entrée un tableau ${\tt T}$ constitué de ${\tt n}$ éléments de type entier et trient le tableau passé en entrée. Elles ne renvoient rien.
Q2 Tester vos fonction avec des tableaux de chaînes de caractères.
Q3 (Mines IPT 2016). On souhaite, partant d’une liste constituéee de couples (chaîne, entier), trier la liste par ordre
croissant de l’entier associe suivant le fonctionnement suivant:
${\tt >>> L = [["Bresil", 76], ["Kenya", 26017], ["Ouganda", 8431]]}$
${\tt >>> tri}\_{\tt chaine(L)}$
${\tt >>> L}$
${\tt [["Bresil", 76], ["Ouganda", 8431], ["Kenya", 26017]]}$
En utilisant une des trois fonctions précédentes (à vous de choisir), écrire en Python une fonction ${\tt tri}\_{\tt chaine}$ realisant cette opération.
Pour évaluer les performances d’un algorithme, on va procéder à une estimation empirique comparée du coût calculatoire des algorithmes par insertion, sélection et à bulles.
Le résultat attendu est représenté ci-dessous.
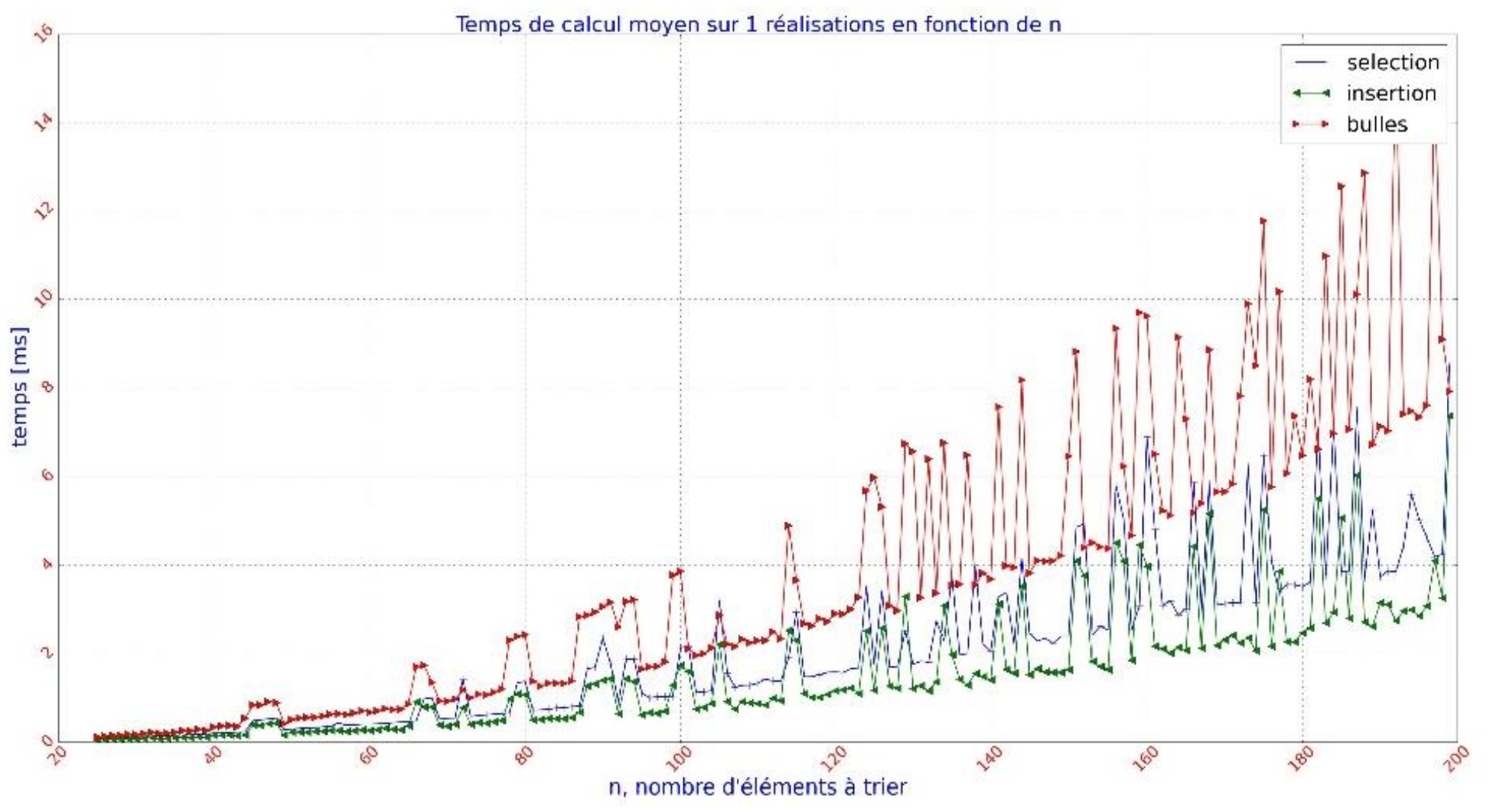
Q4 Ecrivez une fonction qui permet d’estimer le coût calculatoire de chacun des algorithmes et de les comparer sur un même plot comme représenté sur la figure ci-dessus.
On pourra créer un tableau aléatoire de taille n avec l'instruction:
T = [randint(-100000, 100000) for k in range(n) ]
où ${\tt randint}$ est une instruction disponible dans le module ${\tt random}$.
On rappelle qu'on peut mesurer le temps d'exécution de l'instruction ${\tt tri(L)}$ avec les commandes:
from time import time
start = time()
tri(L)
end = time()
duree = end - start
On rappelle aussi que si des points du plan sont définis par la liste ${\tt X}$ de leurs abscisses et la liste ${\tt Y}$ de leurs ordonnées, alors on obtient la ligne brisée les reliant avec l'instruction:
plot(X, Y, label='nom du tri', marker='+', markersize=15, linewidth=2)
où ${\tt plot}$ est une instruction du module ${\tt matplotlib}$.
Le tri par dénombrement est l’un des algorithmes de tri le plus rapide, et pourtant il est loin d'être compliqué, même s'il a quelques restrictions et défauts. Le tri s'exécute en un temps linéaire, mais uniquement sur des nombres entiers.
Le principe est simple, on parcourt le tableau et on compte le nombre de fois que chaque élément apparaît. Une fois qu’on a le tableau des effectifs ${\tt E}$ (avec ${\tt E[i]}$ le nombre de fois où ${\tt i}$ apparaît dans le tableau), on peut le parcourir dans le sens croissant (pour un tri croissant) et placer dans le tableau trié ${\tt E[i]}$ fois l’élément ${\tt i}$ (avec ${\tt i}$ allant de l’élément minimum du tableau jusqu’à l’élément maximum).
Ce tri n'est donc pas fait en place puisqu'on utilise un second tableau pour donner le résultat trié.
Voici un tableau d’entier que l’on souhaite trier dans l’ordre croissant en utilisant le tri par dénombrement : 8, 6, 1, 3, 8, 1, 1.
La première étape est de créer notre tableau des effectifs ${\tt E}$, la deuxième est simplement de le parcourir et de recopier dans le tableau trié les valeurs :
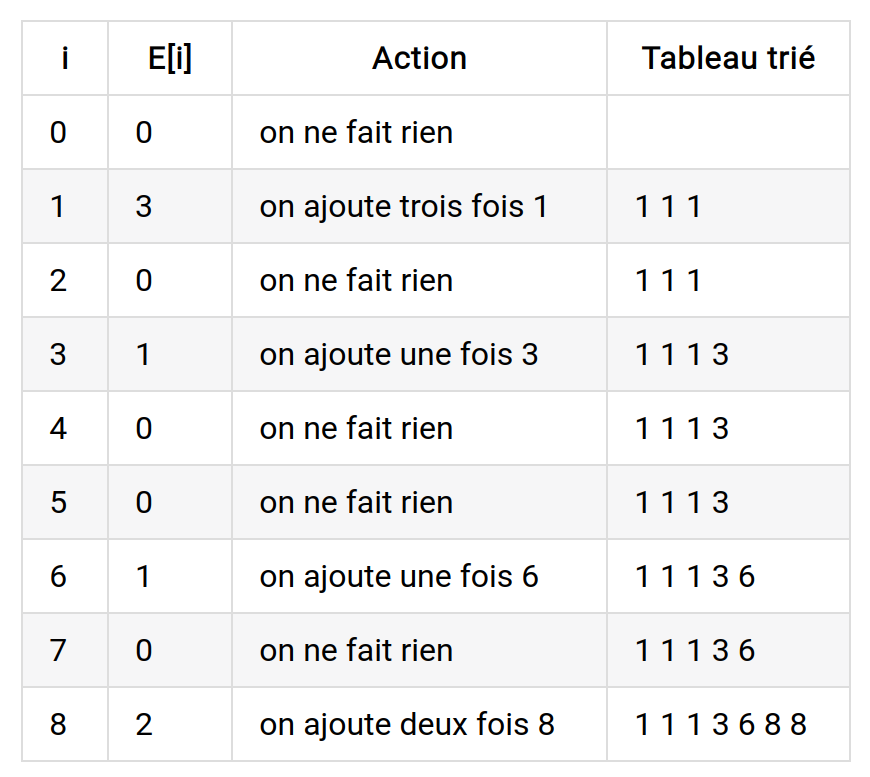
On a atteint le maximum de notre tableau des effectifs E, notre tableau est donc trié: 1, 1, 1, 3, 6, 8, 8.
Q5 Ecrire une fonction ${\tt tridenomb(T)}$ qui a pour argument d’entrée un tableau ${\tt T}$ constitué de ${\tt n}$ éléments de type entier et renvoie une version triée de ce tableau (donc contrairement aux fonctions écrites en Q1 cette fonction renvoie un tableau et ne modifie pas le tableau initial ${\tt T}$).